Controlling Access To S3 Buckets - The Right Way
Amazon makes it pretty straightforward to control access to your S3 buckets - any libary interacting with your S3 bucket will need to supply an access key and a secret key. These are both linked to an Amazon user account which has access to the bucket.
Unfortunately many users simply use the credentials to the root account in order to access the S3 bucket. This is very dangerous - if the access keys are compromised they would give complete access to all your Amazon services. All your data would effectively be compromised. It also means that a configuration bug could be disasterous - for example, if you specify the wrong bucket name you could potentially send data to the wrong bucket or - even worse - accidentally delete critical information from the wrong bucket.
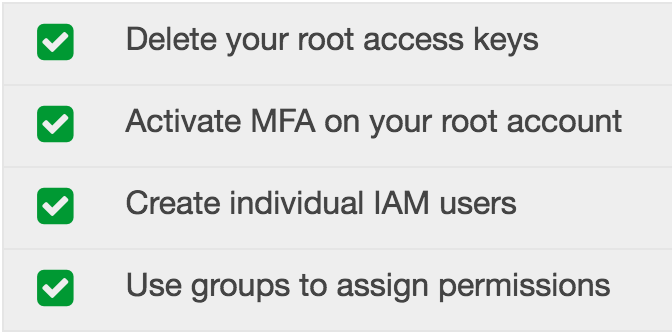
Amazon recommends that you don’t maintain access keys to your root account (for the reasons I stated) and suggest that you use individual user accounts to access different Amazon services. Let’s see what that looks like.
Create the Bucket and User Account
I’m going to setup a new bucket to illustrate how we would go about configuring access to this bucket. Keep in mind that bucket names are unique across all of Amazon, so it’s a good idea to have some kind of naming convention - one that is intuitive between environments. I usually go with environment.yoursite.com and I will be using this convention later on to show how we can configure access for multiple environments.
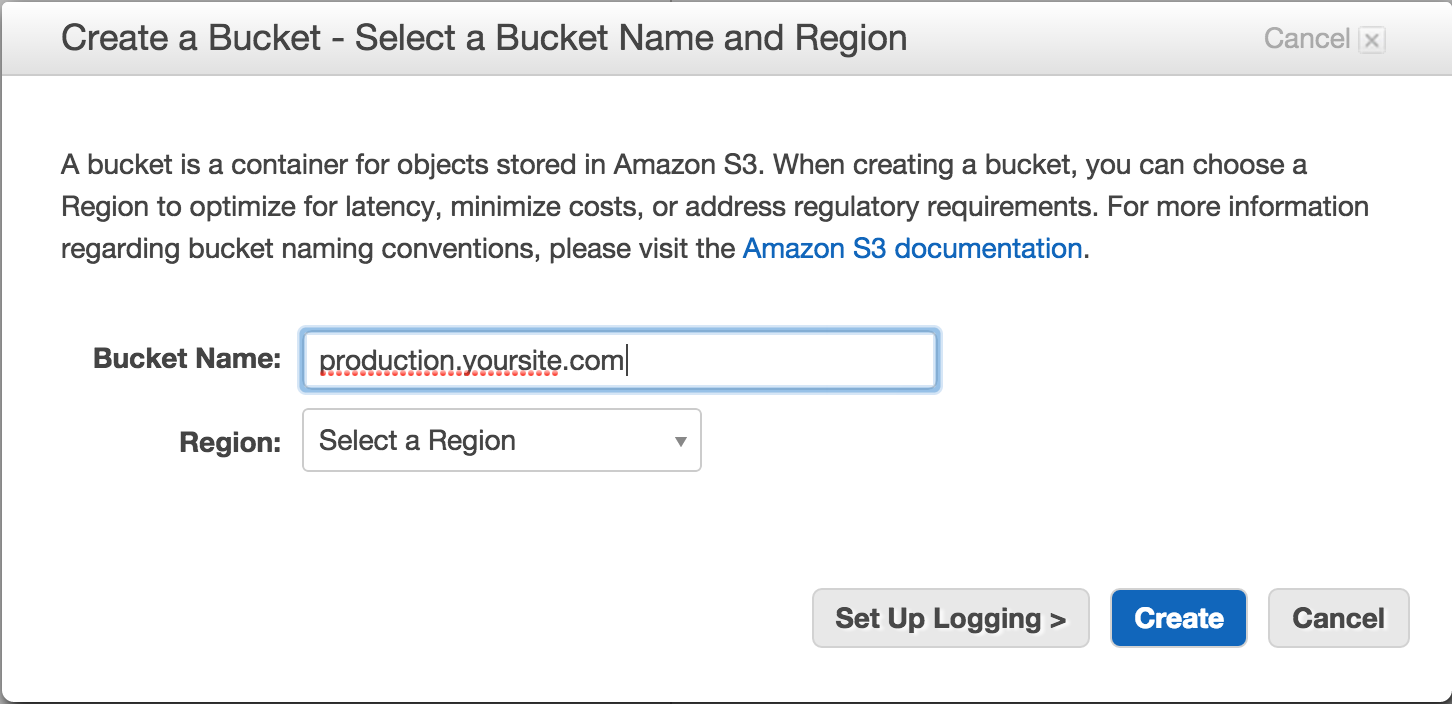
Once we have our bucket we have to decide how we will go about configuring access to the bucket. The best practice here is to have a single user per bucket. So if we have different environments with their own buckets - for example, qa.yoursite.com, staging.yoursite.com and production.yoursite.com - each environment will have a different user account to access their bucket.
Inside the IAM service we can setup the different user accounts we need.
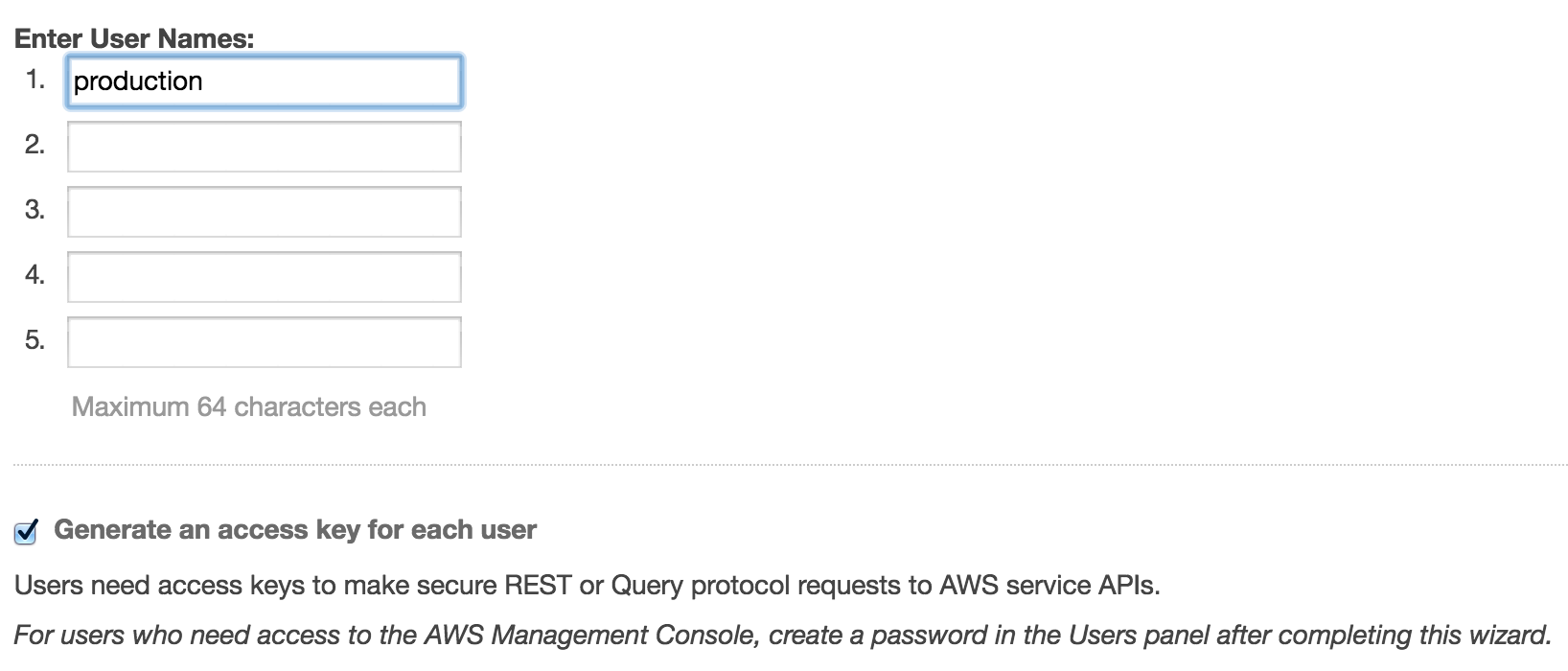
Notice that I am following the same naming convention as above - the name of the user account is the same as the environment name. You obviously don’t have to follow this naming convention, but I highly recommend that you have some kind of naming convention between the name of the environment, the name of the user account and the name of the S3 bucket.
Configure Access to a Single S3 Bucket
Within IAM select the user we just created and then choose ‘Create User Policy’. Choose ‘Custom Policy’. Now we want to specify that this user can perform all actions on the bucket we just created.
The policy might look something like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": "arn:aws:s3:::production.yoursite.com/*"
}
]
}In this policy I am allowing full access to all S3 actions - "Action": "s3:*" - but only to the bucket we just created - "Resource": "arn:aws:s3:::production.yoursite.com/*". Amazon provides a unique identifier (Amazon Resource Name) for each S3 resource. This allows us to restrict access to the specified bucket. You can also test the policy with the Policy Simulator, although the UI is rather clunky.
Configuring Permissions for Multiple Environments, Buckets and Users
We have successfully configured access for a single user, but what happens if we have multiple environments? Best practice would dictate that we have multiple buckets, which means multiple users. Do we have to create a custom policy for every single user? This would be rather tedious and error-prone - it would be rather easy to copy and paste the policy from a previous user and get something wrong.
Luckily Amazon allows us to use variables inside our policies. This is where having a strong naming convention around your environments, buckets and users can be very useful. To recap, in this scenario I am configuring access from the production environment to a bucket aptly named production.yoursite.com via a user named production. I can use this naming convention to make the policy more generic.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": "arn:aws:s3:::${aws:username}.yoursite.com/*"
}
]
}Now we have a generic policy that can be applied to multiple buckets and users. Instead of having to specify this policy for each user we can now add all the users to a group, and apply the policy to the entire group! This means we can easily configure additional environments as long as we stick to the naming convention we picked. The key is that your user names need to be a subset of the bucket names for this approach to work.
I think this is a strong step forward for preventing accidental or unauthorized access to your S3 buckets. The only downside is that Amazon does not provide a unique identifier (Amazon Resource Name) for all resources - for example, you cannot restrict access to a single CloudFront distribution - you have to grant the user access to all CloudFront distributions. Hopefully Amazon will improve this area in the future. Happy coding.